from Kais:
You are welcome to discuss, if you feel the need!
Recall that first comment needs moderation. Other than that, please be constructive, as usual.
Thanks Kais!
from Kais:
I have to record this ongoing discussion from G+, it’s too interesting. Shall do it from my subjective viewpoint, be free to comment on this, either here or in the original place.
(Did the almost the same, i.e. saved here some of my comments from an older discussion, in the post Model of computation vs programming language in molecular computing. That recording was significant, for me at least, because I made those comments by thinking at the work on the GLC actors article, which was then in preparation.)
Further I shall only lightly edit the content of the discussion (for example by adding links).
It started from this post:
From this hypothesis, I believe that notions like “state”, “information”, “signal”, “bit”, are concepts which don’t pass this filter, which is why they are part of an ideology which impedes the understanding of many wonderful things which are discovered lately, somehow against this ideology. Again, Nature is a bitch, not a bit 🙂
That is why, instead of boasting against this ideology and jumping to consciousness (which I think is something which will wait for understanding sometimes very far in the future), I prefer to offer first an alternative (that’s GLC, chemlambda) which shows that it is indeed possible to do anything which can be done with these ways of thinking coming from the age of the invention of the telephone. And then more.
___________________________
]
___________________________
The Autoverse is an artificial life simulator based on a cellular automaton complex enough to represent the substratum of an artificial chemistry. It is deterministic, internally consistent and vaguely resembles real chemistry. Tiny environments, simulated in the Autoverse and filled with populations of a simple, designed lifeform, Autobacterium lamberti, are maintained by a community of enthusiasts obsessed with getting A. lamberti to evolve, something the Autoverse chemistry seems to make extremely difficult.
Related explorations go on in virtual realities (VR) which make extensive use of patchwork heuristics to crudely simulate immersive and convincing physical environments, albeit at a maximum speed of seventeen times slower than “real” time, limited by the optical crystal computing technology used at the time of the story. Larger VR environments, covering a greater internal volume in greater detail, are cost-prohibitive even though VR worlds are computed selectively for inhabitants, reducing redundancy and extraneous objects and places to the minimum details required to provide a convincing experience to those inhabitants; for example, a mirror not being looked at would be reduced to a reflection value, with details being “filled in” as necessary if its owner were to turn their model-of-a-head towards it.
]
___________________________
A very deep one, maybe.
I was looking for news about UD and euclideon. I found this pair of videos [source], the first by BetterReality and the second by The Farm 51 .
Now, suppose that we scanned the whole world (or a part of it) and we put the data in the cloud. Do we have a mirror of reality now on the cloud? No! Why not, the data, according to mainstream CS ideology, is the same: coordinates and tags (color, texture, etc) in the cloud, the same in reality.
Think about the IoT, we do have the objects, lots of them, in potentially unlimited detail. But there is still this uncanny valley between reality and computation.
We can’t use the data, because:
I think that we can use the data (after reformatting it) and we can pass the uncanny valley between reality and computing. A way to do this supposes that:
This is fully compatible with the response given by Neil Gershenfeld to the question
(Thank you Stephen P. King for the G+ post which made me aware of that!)
In the post My idea about UD, completely unrelated to the content of it, b@b made a comment where he gives a link to a post of “BruceRDell” reproduced here:
Okay, I see you understand basic principles. Now let’s move to the more complex things. I can’t share exact UD algorithm (you must understand me, I’ve spent years mastering it) but I can express in a code what I have already said in the interviews. The thing I want to say is: you must use sorting and eliminate raycasting.
Sorting algorithm I introduce here is very VERY simple. You can optimize it a lot using octrees and more elegant heuristics than that. But keep it simple.
You’ve mentioned this http://rghost.net/48541594 dataset, I had some problems downloading it, but I did it that and can say it is good for testing, you may use it with my program.Here is the code I am talking about. If you’re smart enough, you’ll get benefit from it.
Magio, in this comment on My idea about UD, says:
I’m probably way too late for this. But anyway I made this quick edit of the program:
http://pastebin.com/HiDW5tMB[updated version:http://pastebin.com/kW1t5s1c ]
___________________
Question: why does it work?
UPDATE: It’s not clear if it really works, it’s unknown the quantitative improvement given by the random permutation trick. If you care, the BruceRDell thing is a prank.
___________________
I would like to understand the following:
So, let’s have a polite and informative discussion in the comments, if you agree. We all write in some variant of broken english, therefore I don’t see why anybody can’t participate.
___________________
Not interested in: is the real Bruce Dell? Is the real UD algorithm? Only interested to understand the guts of it.
I finish with the video from b@b’s comment:
Here is what I believe that UD is doing. This can be surely multiply optimized, but the basics is: put the z buffer in the 3d space.
I. Preparing the database.
1. Imagine a 3D cubic lattice which is as big as your 3D scenery bounding box. Take coordinates aligned with the lattice. Put the camera at coordinates (0,0,0) and surround it with a cube C. The faces of the cube C will serve as the cubemap we want to construct. Each face is covered by pixels of a given resolution. We have already the following parameters to play with, given in the units of the coordinate system chosen: the step of the lattice, the dimension of the cube C, the resolution of a face of C.
2. render, by any means you like, the lattice, as seen from the (0,0,0) pov, on the 6 “screens” -faces of C. We have 6 view frustra, the discussion will be the same for each of them. In order to render them you need to put small balls, or squares facing the relevant face of the cubemap, or whatever, at the lattice nodes, so we have another parameter here, the diameter of the ball or square. As a result of the rendering you now know the following things:
Of course, you don’t want to take a huge lattice, with very small balls. That’s all in the parameters choice.
3. Take now your database of 3D points, i.e. the real one, which you want to render eventually, UD style. I shall ignore, for the sake of the argument, how is the database implemented: as an octree or otherwise, or even if the database is made by 3D points or by some more complex objects, like polygons. Put this database in the coordinates chosen first, such that, for example, if you are working with octrees, the cells of the lattice correspond with some level of the octree. Attach to each node of the lattice the supplementary information: the points from the database which are within the ball surrounding the atom, or else the label VOID. Alternatively, think that any point from the database is inside some cell lattice and “project” it on each corner of the the cell lattice (i.e. attach to each lattice atom a list of points from the database which are in the neighbourhood of the lattice atom, the nil list corresponds to VOID)
4. Let’s see what we have, supposing for example that we use octrees. We add the 3D lattice to the 3D database of points (by using lists of points as explained at 3.) and for any lattice atom we attach also the information as explained at point 2.
How to compress this efficiently? There is a new parameter here, namely the level of the octree and also how is the color, for example, information stored in the octree. Of course, this is a matter of recursion, namely at points 1-3 we may take finer and finer resolutions and lattice steps, and so on, starting from a very gross lattice and resolution, etc, then trying to figure a correct recursion procedure. That’s work to be done, is not trivial but it is somehow straightforward once you figure it.
II. The pipeline and rendering.
The problem is that we want to be able to get very very fast, from the database constructed at (I), only the points which are needed for realtime rendering, when the camera is at coordinates (x,y,z).
This problem splits into two different ones:
As a preparation, let’s remark that:
1. We use remark 1 to solve the first problem, namely what comes through the pipeline from the huge 3D database to the pre-rendering buffer B, when we start with the camera at (0,0,0). The buffer contains about (number of pixels) X log(dimension of the world) 3D points, along with pixels coordinates where they project and with SCALE. This is fed directly to the rendering procedure, which you can choose freely, but it is almost trivial.
2. What happens when we move the camera? We update the pre-rendering buffer B, only by updating the pixel and scale information for the 3D points in the buffer D, getting only by a translation (addition) the relevant data from the huge database, in case here are two things which might happen: there is a point which exits the buffer, or there is a hole in the image.
_________________________
Is this making any sense? Please let me know, because I was asked repeatedly what do I really believe.
The comments from Is 3D Cube a predecessor of UD? were very useful as concerns the idea of making open source UD like programs. There are already two projects, created by Bauke and Jim respectively, see the page UD projects here for the relevant links.
We cannot possibly know if any of these two proposals is like Bruce Dell’s UD, but it does not matter much because Bauke and Jim programs may well turn out to be as good as Dell’s, or why not even better. (However, I still want to know how exactly the database of Saj’s 3D Cube is done, because of the claims he made many years ago, which are almost identical with the ones made by Dell, see the link from the beginning of this post.)
Enough chit-chat, the reason for this post is that I suppose new discussions will follow, for example about Bauke’s still pending detailed explanations about his program. Also, any day now Jim might amaze us.
So, please start commenting here instead, if you feel the need to ask or answer questions about the two projects. Or, hey, you are welcome to announce yours!
_________
UPDATE: I add here Bauke’s explanations from this comment :
My algorithm consists of three steps:
1. Preparing the quadtree. (This process is very similar to frustum culling, I’m basically culling all the leaf nodes of the quadtree that are not in the frustum.) This step can be omitted at the cost of higher CPU usage.
2. Computing the cubemap. (Or actually only the visible part, if you did step 1.) It uses the quadtree to do occlusion culling. The quadtree is basically an improved z-buffer, though since the octree is descended in front to back order, it is sufficient to only store ‘rendered’ or ‘not rendered’. It furthermore allows to do constant time depth checks for larger regions.3. Rendering the cubemap. This is just the common cubemap rendering method. I do nothing new here.
My description only explains step 2, as this is the core of my algorithm. Step 1 is an optimization and step 3 is so common that I expect the reader to already know how this step works.
Step 2 does not use the display frustum at all. It does do the perspective. But does so by computing the nearest octree leaf (for the sake of simplicity I’m ignoring the LOD/mipmap/anti-aliassing here) in the intersection of a cone and the octree model. This is shown in the following 2D images:
I don’t know what you mean with ‘scaling of each pixel’, but I believe that scaling of pixels only happens in step 3. In step 1 and 2 I completely ignore that this happens.
I hope this answers your questions. If not, please tell which of the 3 steps you do not understand.
_________
UPDATE: You may like techniques used here [source]
Pablo Hugo Reda has found this old site dedicated to the 3D Cube Project (that’s an even older link sent by appc23, with more access to info), as well as a discussion on the net which looks strangely alike the actual exchanges around UD. There are an exe and a database, as well. I reproduce further some parts, taken from the two links provided by Pablo (only boldfaces by me):
3DCube is as far as I know, a completely different way to store and display complex 3D images. The building atoms of the 3D data structure are lines of pixels, not polygons, bitmaps, or voxels. As explained above, the main objective of the project was to create a system that would allow very complex, elaborate models, with hundreds of structures, which could take up to an entire CD-ROM but require only a small portion of the model to reside in RAM. A large portion of the challenge was coming up with data organization that would allow keeping the model on CD ROM but be capable of displaying the perspective of the entire model instantly at any time. This is possible since the high detail of the model is only needed for elements close to the view point origin. Almost no processing is needed to load the model or its parts from the disk (please notice how quickly the demo initializes). Therefore, the disk activity processing load related to tracking the view point movement is very small – much lower than required for playing a digital video for example.
The algorithm required to display the image at any angle from the view point is quite simple. No floating point calculations, trigonometric functions, or even division instructions are needed, and use of multiplication instructions is very limited. A simple custom hardware utilizing my method could render the image with the same ease as a video card hardware displays the bitmap stored in its video memory. […]
My rendering algorithm is essentially a DSP-type algorithm, working with 64-bit data, which generates the image scan-line by scan-line with operations being mostly adding of 64-bit data. If the 80×86 just had a few more registers, the entire rendering algorithm would use no temporary RAM data (just the CPU registers) and would render the entire image by reading the model and outputting the resulting scan-lines. The biggest current problem in implementing the algorithm now is the necessity to swap the temporary data in and out of the registers to memory.
3D Cube project was originated with the intention of making it a new generation 3D game engine, allowing unprecedented detail and complexity of “virtual worlds” created. After seeing the performance and model sophistication possible with this method, I realized that the possible applications of the method are far beyond just video games. […]
In addition to the above, 3D Cube could allow things like taking pictures of some scene from different directions, building a model out of it. 3D Cube storage method
It’s not a mistake, the text ends like this.
From the discussion, a comment by the 3D Cube creator, S.A. Janczewski:
Well, let us try to clarify the term voxel.
– If a “voxel” can have different color/attribute from each of 6 directions, is it still a voxel?
– If it is not cubical — can have sloped surfaces, is it still a voxel?
– If the six colors of a “voxel” are not at all stored together as a unit, is it still a voxel?
– If the data organization of a 3D engine does not have any kind of data structure that would store data through clear (x,y,z) – coordinate
granularity, is it still a voxel engine?If you answer yes to all the above questions than my engine is a voxel engine but so is any polygon-based engine.
I hope that the above will make it clear that the reasons I did not use the term voxel anywhere were following:
– My method has absolutely nothing in common with commonly known voxel engines or storage techniques
– Since the term voxel is not clearly defined, using it would not contribute anything(rather than confusion) to the descriptions
– Some “voxel engine” techniques are patented — using the term could result in getting myself (without a reason) accused of “patent infringement.”Please forgive me if you somehow interpreted my previous message as criticism of your input. I did however get accused quite a few time of ignorance (not by you) for not using the term voxel in my description and felt it was appropriate to respond to it.
What do you think?
___________
UPDATE: Is maybe relevant for the discussion to state that the goal is to produce an open source variant of an UD like algorithm. As you can see, supposing of course that 3D Cube was indeed a precursor of UD, the problems are the same, i.e. a probably very good idea, with a lot of potential for cash and also a game changer for an industry. Communicating it means loosing an advantage, but not communicating it leads to disbelief. There is a third way, open source. Right, no direct money from it, but everybody benefits and new possibilities open. So, in case you are working on that, don’t be shy or secretive, that’s not the good idea. Share.
That’s a collection of facts which might be interesting for UD seekers. I’ll just dump it and wait for your reaction.
(from this wiki page) “Loren Carpenter is co-founder and chief scientist of Pixar Animation Studios. He is the co-inventor of the Reyes rendering algorithm. … In 1980 he gave a presentation at the SIGGRAPH conference, in which he showed “Vol Libre”, a 2 minute computer generated movie. This showcased his software for generating and rendering fractally generated landscapes, and was met with a standing ovation, and (as Carpenter had hoped) he was immediately invited to work at Lucasfilm‘s Computer Division (which would be come Pixar).[2] There Carpenter worked on the “genesis effect” scene of Star Trek II: The Wrath of Khan, which featured an entire fractally-landscaped planet.[2]
… Carpenter invented the A-buffer hidden surface determination algorithm.”
Here is a link to the paper The A-buffer, an Antialiased Hidden Surface Method (1984), recommended reading.
_____
(from this wiki page) “Hidden surface determination is a process by which surfaces which should not be visible to the user (for example, because they lie behind opaque objects such as walls) are prevented from being rendered. Despite advances in hardware capability there is still a need for advanced rendering algorithms. The responsibility of a rendering engine is to allow for large world spaces and as the world’s size approaches infinity the engine should not slow down but remain at constant speed. Optimising this process relies on being able to ensure the diversion of as few resources as possible towards the rendering of surfaces that will not end up being rendered to the user.
There are many techniques for hidden surface determination. They are fundamentally an exercise in sorting, and usually vary in the order in which the sort is performed and how the problem is subdivided. Sorting large quantities of graphics primitives is usually done by divide and conquer.”
_____
For surfels see this page.
Surfels: Surface Elements as Rendering Primitives
H. Pfister, M. Zwicker, J. van Baar, M. Gross, SIGGRAPH 2000
A Survey and Classification of Real Time Rendering Methods
M. Zwicker, M. Gross, H. Pfister
Technical Report No. 332, Computer Science Department, ETH Zürich, 1999.
From the first mentioned article: “In this paper we propose a new method of rendering objects with rich shapes and textures at interactive frame rates. Our rendering architecture is based on simple surface elements (surfels) as rendering primitives. Surfels are point samples of a graphics model. In a preprocessing step, we sample the surfaces of complex geometric models along three orthographic views. At the same time, we perform computation-intensive calculations such as texture, bump, or displacement mapping. By moving rasterization and texturing from the core rendering pipeline to the preprocessing step, we dramatically reduce the rendering cost.”
______
Does it look a bit familiar?
The following is the first guest post, answering the invitation made in Call for analysis of the new UD video . The author is Bauke Conijn (aka bcmpinc). Reposted on his blog here.
______________
I designed an algorithm that, given an octree and a location within that octree can compute the cubemap at that location. The algorithm kind of raytraces each face of the cubemap, but does this in such a way that multiple rays are traced simultaneously (aka. mass connected processing).
The faces of the cubemap are axis-aligned, which allows us to use linear interpolation rather than perspective correct interpolation (which includes 2 multiplications and a division). Because of this linear
interpolation, the algorithm only needs integer additions, subtractions, and multiplications by a power of two (aka. bitshifts).
For a more thorough explanation of the algorithm please read this article.
I’ve also written a partial implementation of the algorithm, available at Git-hub, which renders the positive z plane of the cubemap. It currently does so at 2 fps, which, considering I did not yet put effort in optimization and screen space occlusion is not yet implemented, seems promising. The data is still fully loaded into memory at startup. As background I render a fixed cubemap.
Due to space considerations, not all models have been uploaded to git-hub, but a small low-resolution model is available, such that after compiling the code, you can at least see something. The code is rather messy as it is still in an experimental state.
Images: http://imageshack.us/a/img839/7291/voxel2.png (test-scene) http://imageshack.us/a/img841/1796/voxel3.png (test-scene) http://imageshack.us/a/img708/221/voxel4.png (part of Mouna Loa) http://imageshack.us/a/img24/8798/voxel5.png (part of Mouna Loa) http://imageshack.us/a/img69/2483/voxel6.png (low resolution) _______________ UPDATE: Here is a movie made by Bauke, with his program. Moreover, here is a draft article which explains it in detail.
Thanks to preda and to appc23 for showing us the new UD video:
The previous post on this subject, New discussion on UD (updated) , has lots of interesting comments. It has become difficult to make sense of the various proposals concerning the UD algorithm, therefore I made this new post which shall serve first as a place for new discussions, then it will be updated.
It is maybe the time to make sense a bit of the material existent (or linked to) on this blog. That is why I invite everybody who is willing to do this to make it’s own proposal, preferably with (either) programs or proofs or evidence (links). Especially, in a random order, this invitation is addressed to:
but anybody which has something coherent to communicate is welcome to make a proposal which will blow our minds.
Make your respective proposals as detailed as you wish, take your time to make them convincing and then, if you agree, of course, we shall make feature posts here with each of them, in order to become easier to follow the different threads.
Let me finish, for the moment, by stating which points are the most important in my opinion, until now (I stress, in my opinion, feel free to contradict me):
Almost finished, but I have to explain a bit my attitude about UD. I am thorn between my curiosity about this, explained in other posts (for example by it’s partial overlap with the goals of Digital Materialization), and the fact that I don’t want this blog to be absorbed into this subject only. I have my ideas concerning a possible UD algorithm, especially from a math viewpoint, but unless I produce a program, I can’t know if I’m right or wrong (and I am not willing to try yet, because I am sympathetic with the underdog Dell and also because it would take me at least several months to get off the rust from my programming brain and I am not yet willing to spent real research time on this). Suppose I’m wrong, therefore, and let’s try to find it in a collaborative, open way. If we succeed then I would be very happy, in particular because it would get out of my mind.
This post is for a new discussion on UD, because the older ones “Discussion about how an UD algorithm might work” and “Unlimited detail challenge: the most easy formulation” have lots of comments.
____________
UPDATE: It looks like Oliver Kreylos (go and read his blog as well) extremely interesting work on LiDAR Visualization is very close to Bruce Dell’s Geoverse. Thanks to Dave H. (see comments further) for letting me know about this. It is more and more puzzling why UD was welcomed by so much rejection and so many hate messages when, it turns out, slowly but surely, that’s one of the future hot topics.
____________
Please post here any new comment and I shall update this post with relevant information. We are close to a solution (maybe different than the original), thanks to several contributors, this project begins to look like a real collaborative one.
Note: please don’t get worried if your comment does not appear immediately, this might be due to the fact that it contains links (which is good!) or other quirks of the wordpress filtering of comments, which makes that sometimes I have to approve comments by people who already have previous approved comments. (Also, mind that the first comment you make have to be approved, the following ones are free of approval, unless the previous remarks apply.)
Let’s talk!
I am continuing the post Applications of UD by two comments, one concerning Google, the other Kinect.
Google: There are many discussions (on G+ in particular) around A second spring of cleaning at Google, mainly about their decision concerning Google Reader. But have you notice they are closing Google Building Maker? The reason is this:
Compare with Aerometrex, which uses UD:
So, are we going to see application 2 from the last post (Google Earth with UD) really soon?
Kinect: (I moved the update from the previous post here and slightly modified) Take a look at the video from Kinect + Brain Scan = Augmented Reality for Neurosurgeons
They propose the following strategy:
This is very much compatible with the UD way (see application point 3.) Suppose you have a detailed brain scan, much more detailed than Kinect alone can handle. Why not using UD for the first step, then use Kinect for the second step. First put the scan data into the UD format, then use the UD machine to stream only the necessary data to the Kinect system. This way you have best of both worlds. The neurosurgeon could really see microscopic detail, if needed, correctly mapped inside patient’s brain. What about microscopic level reconstruction of the brain, which is the real level of detail needed by the neurosurgeon?
Where is this fascination about UD from? Think about it a bit from a visual point of view (and mind that I am not writing about the exact, whatever it turns out to be, algorithm, but about principles). The information coming to the brain by the visual path is ridiculously small compared to the complexity of the world. Yes, when we look at something, the world takes care of the intricacies of ray-tracing for us. But what about the visual world reconstructed in our brains? There is no ray-tracing, there are no octrees, nor coordinates. Again, I repeat that despite all the very useful knowledge people have about robotic vision, this knowledge fails spectacularly to explain how we, humans, or simple creatures like flies, see. This cartezian point of view, based on coordinatizing the exterior world and treating it like a given geographical space, is not, neuroscience tells us, how we manipulate space in the brain. Again , I repeat that algorithms, which are devices invented to solve problems, are not the right mean for trying to understand this problem, despite the amazing ideas that CS might give concerning the understanding of the world as some big system which we act upon and which it acts upon us. That is because our little grey cells (but let us not forget about those of the humble fly) don’t work by proposing themselves to solve problems. This is just another disease inflicted by the cartezian viewpoint. (I hope that at this stage you can still make the difference between mine and the average crackpot’s talking.)
If we look at the other side, the one of neuroscience, what we find? Sloppy data, compared to physics, due to the complexity of the systems studied, lack and even despise of mathematical knowledge, again compared with physics, due to the fact that these new sciences are in their infancy.
But somehow, as it has always been, somewhere there is an armchairian (word invented by Scott Aaronson), an ancient greek philosopher kind, which could get rid of the cartezian disease and see clearly a system through the huge pile of data. My bet goes to a mathematician, but I may be biased.
The least interesting application of UD is in the games industry. Here are some other, more appealing, at least to me:
What else?
UPDATE (20.02.2014): Here is something which would look well together with UD:
This is a continuation of the post “Unlimited detail challenge…“. I am still waiting for a real solution to emerge from the various intriguing ideas. Here I want to comment a bit about the kind of the algorithm UD might be.
Bruce Dell compared it with a search algorithm, more specifically compared it with a search algorithm for words. As everybody knows, words form an ordered set, with the lexicographic order.
Moreover, Dell explains that the thing of UD is to pick from the huge database (which might be in a server, while the algorithm runs on a computer elsewhere, thus the algorithm has to be in a sense an online algorithm) only the 3D atoms which are visible on the screen, then render only those atoms.
Therefore, imagine that we have a huge database of 3D atoms with some characteristics (like color) and a separate database made of the coordinates of these atoms. The UD algorithm solves a “sorting” problem in the second database. (I put “sorting” because there is no total order fully compatible with the solution of the ray-casting problem, in the sense that it remains the same when the POV is changed.) Once this “sorting” part is done, the algorithm asks for the characteristics of only those points and proceed to the rendering part, which is almost trivial.
By looking at sorting algorithms, it is then to be expected a time estimate of the kind 
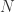
There are even sorting algorithms which are more efficient, like 

So, the bottom line is this: think about UD as being a kind of sorting algorithm.
Thanks to Dave H. for noticing the new Euclideon site!
Now, I propose you to think about the most easy formulation of unlimited detail.
You live in a 2D world, you have a 1D screen which has 4 pixels. You look at the world, through the screen, by using a 90deg frustrum. The 2D world is finite, with diameter N, measured in the unit lengths of the pixels (so the screen has length 4 and your eye is at distance 2 from the screen). The world contains atoms which are located on integer coordinates in the plan. There are no two atoms in the same place. Each atom has attached to it at most P bits, representing its colour. Your position is given by a pair of integer coordinates and the screen points towards N, S, E, W only.
Challenge: give a greedy algorithm which, given your position and the screen direction, it chooses 4 atoms from the world which are visible through the screen, in at most O(log N) steps.
Hints:
_______________
The Teaser 2D UD might help.
I’m not giving this challenge because I am a secretive …. but because I enjoy collaborations.
Here are two images which may (or may not) give an idea about another fast algorithm for real time rendering of 3D point cloud scenes (but attention, the images are drawn for the baby model of 2D point cloud scenes). The secret lies in the database.
I have a busy schedule the next weeks and I have to get it out of my system. Therefore, if anybody gets it then please send me a comment here. Has this been done before, does it work?
The images now: the first has no name

The second image is a photo of the Stoa Poikile, taken from here:

Hint: this is a solution for the ray shooting problem (read it) which eliminates trigonometry, shooting rays, computing intersections, and it uses only addition operation (once the database is well done), moreover, the database organized as in the pictures cannot be bigger than the original one (thus it is also a compression of the original database).
_______________
See the solution given by JX of an unlimited detail algorithm here and here.
Let me tell in plain words the explanation by JX about how a UD algorithm might work (is not just an idea, is supported by proof, experiments, go and see this post).
It is too funny! Is the computer version of a diorama. Is an unlimited-detail-orama.
Before giving the zest of the explanation of JX, let’s thinks: do you ever saw a totally artificial construction which, when you look at it, it tricks your mind to believe you look at an actual, vast piece of landscape, full of infinite detail? Yes, right? This is a serious thing, actually, it poses a lot of questions about how much can be compressed the 3D visual experience of a mind boggling huge database of 3D points.
Indeed, JX explains that his UD type algorithm has two parts:
Now, let me show you this has been done before, in the meatspace. And even more, like animation! Go and read this, is too funny:



(image taken from this wiki page)
Please, JX, correct me if I am wrong.
I offer this post for discussions around UD type algorithms. I shall update this post, each time indicating the original comment with the suggested updates.
[The rule concerning comments on this blog is that the first time you comment, I have to aprove it. I keep the privilege of not accepting or deleting comments which are not constructive]
For other posts here on the subject of UD see the dedicated tag unlimited detail.
I propose you to start from this comment by JX, then we may work on it to make it clear (even for a mathematician). Thank you JX for this comment!
I arranged a bit the comment, [what is written between brackets is my comment]. I numbered each paragraph, for easiness.
Now I worked and thought enough to reveal all the details, lol. [see this comment by JX]
I may dissapoint you: there’s no much mathematics in what I did. JUST SOME VERY ROUGH BRUTE-FORCE TRICKS.1) In short: I render cubemaps but not of pixels – it is cubemaps of 3d points visible from some center.
2) When camera is in that cubemap’s center – all points projected and no holes visible. When camera moves, the world realistically changes in perspective but holes count increases. I combine few snapshots at time to decrease holes count, I also use simple hole filling algorithm. My hole filling algorithm sometimes gives same artifacts as in non-cropped UD videos (bottom and right sides) .
[source JX #2] ( link to the artifacts image )this artifacts can be received after appliying hole-filling algorithm from left to right and then from top to the bottom, this why they appear only on right and bottom sides. Another case is viewport clipping of groups of points arranged into grid: link from my old experiment with such groups.
This confirms that UD has holes too and his claim “exactly one point for each pixel” isn’t true.
3) I used words “special”, “way”, “algorithm” etc just to fog the truth a bit. And there is some problems (with disk space) which doesn’t really bother UD as I understand. [that’s why they moved to geospatial industry] So probably my idea is very far from UD’s secret. Yes, it allows to render huge point clouds but it is stupid and I’m sure now it was done before. Maybe there is possibility to take some ideas from my engine and improve them, so here is the explanation:
4) Yes, I too started this project with this idea: “indexing is the key”. You say to the database: “camera position is XYZ, give me the points”. And there’s files in database with separated points, database just picks up few files and gives them to you. It just can’t be slow. It only may be very heavy-weight (impossible to store such many “panoramas”) .5) I found that instead of keeping _screen pixels_ (like for panoramas) for each millimeter of camera position it is possible to keep actual _point coordinates_ (like single laser scanner frame) and project them again and again while camera moves and fill holes with other points and camera step between those files may be far bigger than millimeters (like for stereo-pairs to see volumetric image you only need two distant “snapshots”).
6) By “points linked with each other” I meant bunch of points linked to the some central points. (by points I mean _visible_ points from central point).
7) What is central point? Consider this as laser scanner frame. Scanner is static and catches points around itself. Point density near scanner is high and vice versa.
8) So again: my engine just switches gradually between virtual “scanner” snapshots of points relative to some center. During real-time presentation, for each frame a few snapshots are projected, more points projected from the nearest, less from far snapshots.
9) Total point count isn’t very big, so real-time isn’t impossible. Some holes appear, simple algorithm fills them using only color and z-buffer data.
10) I receive frames(or snapshots) by projecting all the points using perspective matrix, I use fov 90, 256×256 or 512×512 point buffer (like z-buffer but it stores relative (to the scanner) point position XYZ).11) I do this six times to receive cubemap. Maximum points in the frame is 512x512x6. I can easily do color interpolation for the overlapped points. I don’t pick color of the point from one place. This makes data interleaved and repeated.
12) Next functions allow me to compress point coordinates in snapshots to the 16bit values. Why it works – because we don’t need big precision for distant points, they often don’t change screen position while being moved by small steps.
int32_t expand(int16_t x, float y)
{
int8_t sign = 1;
if (x<0) { sign = -1; x = -x; }
return (x+x*(x*y))*sign;
}int16_t shrink(int32_t z, float y)
{
int8_t sign = 1;
if (z<0) { sign = -1; z = -z; }
return ((sqrtf(4*y*z+1)-1)/(2*y))*sign;
}13) I also compress colors to 16bit. I also compress normals to one 24bit value. I also add shader number (8bit) to the point. So one point in snapshot consists of: 16bit*3 position + 24bit normal + 16bit color + 8bit shader.
14) There must be some ways to compress it more (store colors in texture (lossy jpeg), make some points to share shader and normals). Uncompressed snapshot full of points (this may be indoor snapshot) 512x512x6 = 18Mb , 256x256x6 = 4,5Mb
Of course, after lzma compression (engine reads directly from ulzma output, which is fast) it can be up to 10 times smaller, but sometimes only 2-3 times. AND THIS IS A PROBLEM. I’m afraid, UD has smarter way to index it’s data.
For 320×240 screen resolution 512×512 is enough, 256×256 too, but there will be more holes and quality will suffer.
To summarize engine’s workflow:
15) Snapshot building stage. Render all scene points (any speed-up may be used here: octrees or, what I currently use: dynamic point skipping according to last point distance to the camera) to snapshots and compress them. Step between snapshots increases data weight AND rendering time AND quality. There’s no much sense to make step like 1 point. Or even 100 points. After this, scene is no longer needed or I should say scene won’t be used for realtime rendering.
16) Rendering stage. Load nearest snapshots to the camera and project points from them (more points for closer snapshots, less for distant. 1 main snapshot + ~6-8 additional used at time. (I am still not sure about this scheme and changing it often). Backfa..point culling applied. Shaders applied. Fill holes. Constantly update snapshots array according to the camera position.
17) If I restrict camera positions, it is possible to “compress” huge point cloud level into relatively small database. But in other cases my database will be many times greater than original point cloud scene. [ See comments JX#2 , JX#3 , chorasimilarity#4 , chorasimilarity#5 . Here is an eye-candy image of an experiment by JX, see JX#2:]

Next development steps may be:
18) dynamic camera step during snapshot building (It may be better to do more steps when more points closer to camera (simple to count during projection) and less steps when camera in air above the island, for example),
19) better snapshot compression (jpeg, maybe delta-coding for points), octree involvement during snapshot building.
20) But as I realized disk memory problems, my interest is falling.
Any questions?
I try to formulate the question about how Unlimited Detail works like this:
Let D be a database of 3D points, containing information about M points. Let also S be the image on the screen, say with N pixels. Problem:
Is this reasonable?
For example, take N=1. The finite word means the position and orientation of the screen in the 3D world of the database. If the M points would admit a representation as a number (euclidean invariant hash function?) of order M^a (i.e. polynomial in the number of points), then it would be reasonable to expect D’ to have dimension of order O(log(M)), so in this case simply by traversing D’ we get the time O(log(M)) = O(N log(M)). Even if we cannot make D’ to be O(log(M)) large, maybe the algorithm still takes O(log(M)) steps simply because M is approximately the volume, so the diameter in 3D space is roughly between M^(1/3) and M, or due to scaling of the perspective the algorithm may still hop through D’ in geometric, not arithmetic steps.
The second remark is that there is no restriction for the time which is necessary for transforming D into D’.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}