Here is what I believe that UD is doing. This can be surely multiply optimized, but the basics is: put the z buffer in the 3d space.
I. Preparing the database.
1. Imagine a 3D cubic lattice which is as big as your 3D scenery bounding box. Take coordinates aligned with the lattice. Put the camera at coordinates (0,0,0) and surround it with a cube C. The faces of the cube C will serve as the cubemap we want to construct. Each face is covered by pixels of a given resolution. We have already the following parameters to play with, given in the units of the coordinate system chosen: the step of the lattice, the dimension of the cube C, the resolution of a face of C.
2. render, by any means you like, the lattice, as seen from the (0,0,0) pov, on the 6 “screens” -faces of C. We have 6 view frustra, the discussion will be the same for each of them. In order to render them you need to put small balls, or squares facing the relevant face of the cubemap, or whatever, at the lattice nodes, so we have another parameter here, the diameter of the ball or square. As a result of the rendering you now know the following things:
- for any lattice atom you know which pixel from which face it corresponds. You may do better for lattice atoms which are inside the cube C, namely “ignore” them, say you attribute to them a IGNORE label, otherwise you attribute to each lattice atom the 2D coordinates of the pixel from the cubemap and a information which says which face of the cubemap the pixel is,
- you have information about the scale, which you attach to the lattice atoms, like this: if two neighbouring lattice atoms project on the same pixel then attach IGNORE to both. If the ball/square/whatever of a lattice atom projects on more than one pixel then attach to it a number SCALE approximately proportional with the square ROOT (thanks ine) of the number of pixels it projects (or the dimension of the bounding box of the pixels)
Of course, you don’t want to take a huge lattice, with very small balls. That’s all in the parameters choice.
3. Take now your database of 3D points, i.e. the real one, which you want to render eventually, UD style. I shall ignore, for the sake of the argument, how is the database implemented: as an octree or otherwise, or even if the database is made by 3D points or by some more complex objects, like polygons. Put this database in the coordinates chosen first, such that, for example, if you are working with octrees, the cells of the lattice correspond with some level of the octree. Attach to each node of the lattice the supplementary information: the points from the database which are within the ball surrounding the atom, or else the label VOID. Alternatively, think that any point from the database is inside some cell lattice and “project” it on each corner of the the cell lattice (i.e. attach to each lattice atom a list of points from the database which are in the neighbourhood of the lattice atom, the nil list corresponds to VOID)
4. Let’s see what we have, supposing for example that we use octrees. We add the 3D lattice to the 3D database of points (by using lists of points as explained at 3.) and for any lattice atom we attach also the information as explained at point 2.
How to compress this efficiently? There is a new parameter here, namely the level of the octree and also how is the color, for example, information stored in the octree. Of course, this is a matter of recursion, namely at points 1-3 we may take finer and finer resolutions and lattice steps, and so on, starting from a very gross lattice and resolution, etc, then trying to figure a correct recursion procedure. That’s work to be done, is not trivial but it is somehow straightforward once you figure it.
II. The pipeline and rendering.
The problem is that we want to be able to get very very fast, from the database constructed at (I), only the points which are needed for realtime rendering, when the camera is at coordinates (x,y,z).
This problem splits into two different ones:
- at the start of the realtime UD rendering, we want to be able to cull something close to the minimum number of 3D points, when camera is at (0,0,0). According to the information given by Euclideon, a good algorithm should able to do this in about 1s.
- then, we need a procedure to take what we need from the database when we change the pov from (x,y,z) to (x+1,y, z) (or alike). This should be much more faster, allowing for realtime rendering.
As a preparation, let’s remark that:
- if the camera is a (0,0,0), then we already know where each lattice point projects, is written in the database. So we just need to start from a pixel, at a given resolution (reccursion again), and to choose from the database only the lattice atoms which are CLOSE, in the decreasing order of SCALE, and from those the real 3D points which are neighbours (of course we have to use the octree structure). We get for each pixel a number of points of the order of log(dimension of the world).
- if the camera is at (x,y,z) we also know where each point from the 3D database projects, because we read it from the data attached to the lattice atom which, translated by (x,y,z), is the neighbour of the point. We get also the SCALE parameter from this.
1. We use remark 1 to solve the first problem, namely what comes through the pipeline from the huge 3D database to the pre-rendering buffer B, when we start with the camera at (0,0,0). The buffer contains about (number of pixels) X log(dimension of the world) 3D points, along with pixels coordinates where they project and with SCALE. This is fed directly to the rendering procedure, which you can choose freely, but it is almost trivial.
2. What happens when we move the camera? We update the pre-rendering buffer B, only by updating the pixel and scale information for the 3D points in the buffer D, getting only by a translation (addition) the relevant data from the huge database, in case here are two things which might happen: there is a point which exits the buffer, or there is a hole in the image.
_________________________
Is this making any sense? Please let me know, because I was asked repeatedly what do I really believe.


 (for given, fixed number of screen pixels), where
(for given, fixed number of screen pixels), where 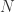 is the number of 3D atoms.
is the number of 3D atoms. , but they are more efficient in practice for really huge numbers of atoms , like
, but they are more efficient in practice for really huge numbers of atoms , like  , as the
, as the 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}