This is a note about a simple use of convex analysis in relation with neural networks. There are many points of contact between convex analysis and neural networks, but I have not been able to locate this one, thanks for pointing me to a source, if any.
Let’s start with a directed graph with set of nodes 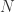
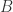


so that for any bond 


For any neuron 
- let
be the set of bonds
,
- let
be the set of bonds
.
A state of the network is a function 

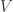

If you think that’s too much, just imagine 

A weight of the network is a function 
Usually the state of the network is described by a function which associates to any bond 


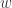
The activation function of a neuron
The integral of an increasing continuous function is a convex function. I’ll call this integral the activation potential 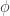
for any neuron 

This relation generalizes to:
for any neuron

where 

Written like this, we are done with any smoothness assumptions, which is one of the strong features of convex analysis.
This subgradient relation also explains the maybe strange definition of states and weights with the vector spaces
This subgradient relation can be expressed as the minimum of a cost function. Indeed, to any convex function 


where 

This sync has the following properties:
- it is convex in each argument
for any
if and only if
.

With the sync we can produce a cost associated to the neuron: for any 

The total cost function 

and it has the following properties:
for any state
if and only if for any neuron
so that’s a good cost function.
Example:
- take
- then the activation function (i.e. the subgradient) is the logistic function
- and the Fenchel dual of the softplus function is the (negative of the) binary entropy
(extended by
for
or
and equal to
outside the closed interval
).

________
[1] Blurred maximal cyclically monotone sets and bipotentials, with Géry de Saxcé and Claude Vallée, Analysis and Applications 8 (2010), no. 4, 1-14, arXiv:0905.0068
_______________________________
