I still don’t know which format is better for Open Science. I’m long past the article format for obvious reasons. Validation is a good word and concept because you don’t have to rely absolutely on opinions of others and that’s how the world works. This is not all the story though.
I am very fortunate to be a mathematician, not a biologist or biochemist. Still I long for the good format for Open Science, even if, as a mathematician, I don’t have the problems biologists or chemists have, namely loads and loads of experimental data and empirical approaches. I do have a world of my own to experiment with, where I do have loads of data and empirical constructs. My mind, my brain are real and I could understand myself by using tools of chemists and biologists to explore the outcomes of my research. Funny right? I can look at myself from the outside.
That is why I chose to not jump directly to make Hydrogen, but instead to treat the chemlambda world, again, as a guinea pig for Open Science.
There are 427 well written molecules in the chemlambda library of molecules on Github. There are 385 posts in the chemlambda collection on Google+, most of them with animations from simulations of those molecules. It is a world, how big is it?
It is easy to make first a one page direct access to the chemlambda collection. It is funnier to build a phylogenetic tree of the molecules, based on their genes. That’s what I am doing now, based on a work in progress.
Each molecule can be decomposed in “genes” say, by a sequencer program. Then one can use a distance between these genes to estimate first how they cluster and later to make a phylogenetic tree.
Here is the first heatmap (using the edit distance between single occurrences of genes in molecules) of the 427 molecules.

Is a screenshot, proving that my custom programs work 🙂 (one understands more by writing some scripts than by taking tools ready made from others, at least at this stage of research).
By using the edit distance I can map the explored chemlambda molecules. In the following image the 427 molecules from the library are represented as nodes and for each pair of molecules at an edit distance at most 20 there is a link. The nodes are in a central gravitational field, each node has the same charge and the links between nodes act as springs.

This is a screenshot of the result, showing clusters and trees, connecting them. Not very sophisticated, but enough to give a sense of the explored territory. In the curated collection, such a map would be useful to navigate through the molecules, as well as for giving ideas about which parts are not as well explored. I have not yet made clear which parts of the map cover lambda terms, which cover quines, etc.
Moreover, I see structure! The 427 molecules are made of copies of 605 different linear “genes” (i.e. sticks with colored ends) and 38 ring shaped ones. (Is easy to prove that lambda terms have no rings, when turned into molecules.) There are some interesting curved features visible in the edit distance of the sticks.
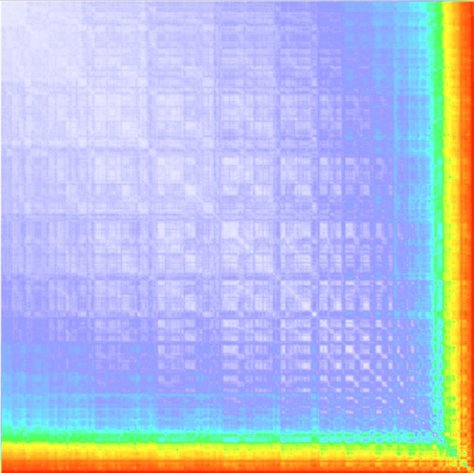
They don’t look random enough.
Is clear that a phylogenetic tree is in reach, then what else than connecting the G+ collection posts with the molecules used, arranged along the tree…?
Can I discover which molecules are coming from lambda terms?
Can I discover how my mind worked when building these molecules?
Which are the neglected sides, the blind places?
I hope to be able to tell by the numbers.
Which brings me to the main subject of this post: which is a good format for an Open Science piece of research?
Right now I am in between two variants, which may turn out to not be as different as they seem. An OS research vehicle could be:
- like a viable living organism, literary
- or like a viable world, literary.
Only the future will tell which is which. Maybe both!
