Are these:
– Digital Materialization (DM)
– Euclideon (Unlimited Detail)
related? Can be this rather simple (from a pure math viewpoint) research program doable and moreover DONE by anybody?
Let me explain. My wonder came after searching with google for
– “Digital materialization” AND “euclideon” – no answers
– “Digital materialization” AND “Fractal image compression” – no answers
– “Fractal image compression” AND “euclideon” – no answers
1. Cite from the Digital Materialization Group homepage:
Digital Materialization (DM) can loosely be defined as two-way direct communication or conversion between matter and information that enable people to exactly describe, monitor, manipulate and create any arbitrary real object. DM is a general paradigm alongside a specified framework that is suitable for computer processing and includes: holistic, coherent, volumetric modeling systems; symbolic languages that are able to handle infinite degrees of freedom and detail in a compact format; and the direct interaction and/or fabrication of any object at any spatial resolution without the need for “lossy” or intermediate formats.
DM systems possess the following attributes:
- realistic – correct spatial mapping of matter to information
- exact – exact language and/or methods for input from and output to matter
- infinite – ability to operate at any scale and define infinite detail
- symbolic – accessible to individuals for design, creation and modification
As far as I understand, this works based on Function Representation (FREP), see HyperFun.org . The idea is to define an object in 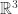



In particular, we may easily pass to polar coordinates based on the point of view and stay in this coordinate system for visualization.
2. Fractal image compression is based on the fact that any compact set (like an image, described as a compact set in the 5D space = 2D (spatial) times 3D (RGB levels)) can be described as a fixed point of an iterated function system.
This brings me to
PROBLEM 1: Is there any version of the Hutchinson theorem about fixed points of IFS, with the space of compact sets replaced by a space of FREP functions? Correspondingly, is there a “FREP compression algorithm”?
My guess is that the answer is YES. Let’s assume it is so.
3. In the article “Digital Foundry vs. Unlimited Detail” it is reported the following 2008 post by Bruce Dell:
Hi every one , I’m Bruce Dell (though I’m not entirely sure how I prove that on a forum)
Any way: firstly the system isn’t ray tracing at all or anything like ray tracing. Ray tracing uses up lots of nasty multiplication and divide operators and so isn’t very fast or friendly.
Unlimited Detail is a sorting algorithm that retrieves only the 3d atoms (I wont say voxels any more it seems that word doesn’t have the prestige in the games industry that it enjoys in medicine and the sciences) that are needed, exactly one for each pixel on the screen, it displays them using a very different procedure from individual 3d to 2d conversion, instead we use a mass 3d to 2d conversion that shares the common elements of the 2d positions of all the dots combined. And so we get lots of geometry and lots of speed, speed isn’t fantastic yet compared to hardware, but its very good for a software application that’s not written for dual core. We get about 24-30 fps 1024*768 for that demo of the pyramids of monsters. The media is hyping up the death of polygons but really that’s just not practical, this will probably be released as “backgrounds only” for the next few years, until we have made a lot more tools to work with.
Assuming that we take a database representing a 3D very complex object (like a piece of landscape) and we convert it, by using a FREP compression algorithm, into a tree as described at point 1, then it becomes easy to imagine how the Unlimited Detail algorithm might work.
Problem 2: Given a FREP representation of a collection of 3D objects, describe an efficient sorting algorithm which uses the representation and outputs the part of the union of object visible from a given point at infinity.
Conclusion: unless this is utter giberish, the modus operandi of an “unlimited detail” algorithm could be the following:
1)- start with a database of a collection of 3d objects and compress it into a FREP format
2)- perform a “mass 3d to 2d conversion”, by using a solution of the problem 2, in polar coordinated from the viewpoint.

Well I have been working on Frep / hyper fun for many years. Its very real and it works. If there is hype its that in the excitement of what it can do people will forget is very limited as to size of the objects for now it requires a massive amount of computational resources.
So we all know people will be disappointed and critical of SymVo because it will allow them to make very complex volumetric objects, but will be limited in size because of the need for greater computational resources. We our selfs are upset at the limits of current computational resources.
However it has many uses for now and is already critical to controlling 3D machines. SymVol will be the key hole killer application for quantum computing and be a reason for pushing the development of quantum computing. Its been my dream and others for many years.
Its just to good to be true, but it is. Down load it and find out… You can also download the journal papers and read them to understand how it works.
The work is profound, hard to understand and rejected by many people, but the work continues to move forward.. a new field of math is needed … and expansion into many different area of research can be undertaking. Like lisp special CPU and processing chips can be made that will make the computations for SymVol orders of magnitude faster.
Very curious to hear about “a new field of math is needed”, here or look for my e-mail in the last arxiv paper.
I don’t think it’s hype, I only suggested that, in specific ways, the “unlimited detail” algorithm (which works, that’s my opinion!) may use frep ideas (which implies that possibly you, the frep community, may have interesting discussions with Euclideon, at least about the visualization part).
Hi, guys, I think, I know, how it works, I am working on my own UD engine now, it does pretty well and have same features Dell described in his UD. But i’m in doubts (cause this all is still very exciting for me): should I reveal all the details to the world or contact Bruce Dell (why?) or should I start my own company or what?? I am asking you, because you are searching for the answer too and you may have some plans in mind for the case when you’ll find out. (Sorry for my Engrish, I am from USSR).
You choose. It would be great if you could post some proof of your claims.
Well all the heavy lifting for DU has been done and the majority of it was done by Russian’s. I gave presentations in Russia and a talk at University of Moscow. Please read the many journal papers on Hyper Fun, Frep, implicit objects surfaces. Parts of Symvol will be open source in 2013 or 2014… You can perhaps contact Uformia CTO Trulif Vilbrandt if you want to join the efforts. The basic algorithm (fastest in the world) for sorting out features was develop by a student of mine for his masters. It has been improved upon and integrated into SymVol. It took my Russian colleges almost a year to believe what my Japanese student had done. If you want to do the same … first like my student did … you need to look at all the sorting algorithms and analysis them. You also have to understand the unique scientific challenges in shape modeling… ie find the state of the art…. who did what where… perhaps you may come up with a better way… the UD does not come from some sorting algorithm. It comes from Frep… what you mean by UD and we mean by Unlimited resolution independence or Unlimited dimensions or attributes … So you missing the core of the value of the work by a great distance… its like your thinking about some visual game… UD… when its about synthetic worlds … the extensions of the natural world.
If you want any more help.. then you will need to agree to CGPL.org..
some text I am working on:
The development of the constructs of digital materialism began with a simple question coming to mind after using a computer for about six months “what is the material being used?” or “what is digital material?” and “how does its use change social structures?”. A study referred to as history materialism.
It took three years to begin to form acceptable answers to the questions, then shortly after the rudimentary practicable and theoretical constructs were formed a environmental preservationist stratagem of leap frogging into the future emerged during a violent police reaction to an environmental protest. It was to entangle a trinity of ethics where environmental sustainable above all else is given legal standing with the research, development and use of digital materialism technologies and their derivatives.
Common Good Public License: Digital Freedom, Human Rights and Environmental Sustainability above all. A trinity of common global ethics above that of the laws of nation states, the religious morality and culture mores, that is the separation of global governance from the laws of nation states, church and local cultures.
It is the essential natural structure of digital data. It is a computational based precise language of men and machines were the transmigration of natural objects and information into fungible knowledge contained within digital objects living within a virtual cyber space followed by the materialization or tangible reincarnation of such synthetic objects a necessary “physical Turing test” for confirming the veracities of such “artificial” compilation or synthetic evolution. Were informational space libraries has changed from the containment in books and the Dewie decimal index to containment and inclusive indexing in digital objects and just in time retrieval of a collection of knowledge.
Digital materialism is about the presto of a natural object at a distance. It is metaphorically the end of ordinary reality revealing a computational geometrical Pythagorean unity of mysticism and science in which, existence and eschatology are separated in degrees measured by the amount of available computational resources. It could be said to be the Pythagorean proof of the holistic divinity of life, science and mathematics.
Dear Carl, I like the idea of DM, that is why I gave links to the wiki page and your google+ account. But I am also a mathematician and I like precise formulations whenever possible. As an example, what do you mean by “… the UD does not come from some sorting algorithm. It comes from Frep…”, because for me UD is “Unlimited Detail”, by the australian Bruce Dell.
I understand the math behind Frep, my concern is to understand the format used by Bruce Dell, because I believe it may be related to some of my mathematical preoccupations. But what is explained in the post, in some detail, is that by reformulating fractal image compression in terms of freps one might encode loads of 3D data in a way which could be used later by a fast “search algorithm” as Dell described his UD. So, the most important thing to understand is that behind the UD (australian) idea lies a clever file format for huge quantites of 3D data.
That is why my suggestion in the posts about DM and Euclideon is that there might be some place for a dialogue. I would do it, if I were involved. Your choice, is just a suggestion, no need to become overprotective because I don’t have anything into this.
As for “You can perhaps contact Uformia CTO Trulif Vilbrandt if you want to join the efforts”, I use to be rather expensive 😉 .
I’ve just started, there’s a lot of work to do yet, here is some description of what i have now with screenshot:
First two is stereo pair, third shows depth (i added lot of contrast in image editor, that’s why it got artifacts).
Forgot to say: I also don’t use octree or any tree for now. Neither DM (don’t even understood it fully). Can’t reveal more info or decide to release source or not, must do more work on it first, sorry.
Do you mind if I put your message, with the image, in a post? Let’s see what happens!
OK, it looks good. Re: “Can’t reveal more info…”, could you at least tell me how do you keep the 3D data? Describe the database, in principle? If I were you, I would post a paper on arxiv which describes some of the details, because it is about math and because arxiv is a long term repository which records the time when you post it (and because I am curious about this 🙂 ).
Hi JX, I suppose you know about these videos here and here. They look much more impressive than your linked image, only they declare doing it by using octrees, while you claim you do it unlimited detail style.
Yes, I saw that videos and as I understand from comments, whole model lays in RAM and scene is assembled using links to that one model and this method consumes too much RAM, so I doubt that scenes can be streamed or be really unique. This is very different from my system.
My method uses streaming (can be compared to watching videos – you only need to keep loading small parts into buffer no matter how big the video is) so it is possible to keep all the data on single server and not to worry about data size.
Database? It’s just points (normals (not necessary though but useful when applying specular shaders, each point also can store shader number (256 possible shaders), colors (compressed, and with lod layers (not used yet), position (relative to some centers), some my own compression algorithms + lzma over it. And all these points sorted and linked with each other (allows to do streaming and to compress position data) in special way.
Octrees will be very helpful in my system (and I plan to use them) BUT: only to speed up data sorting/conversion and maybe to precalculate lighting. Can’t think of benefit from octrees during realtime rendering.
(Haven’t much time last week to code, so no progress yet.)
Thanks JX, I shall update the last post. Re: “all these points sorted and linked with each other … in special way”. That is what I want to understand, from pure mathematical reasons. Could you tell me this? Look for my mail in the About post. I shall acknowledge you in any mathematical paper where I use this, of course.
JX’s comments confirm my guess that database is the key. It has to be something which answers the question: how to embedd a well selected family of euclidean invariants into the structure (linking, sorting) of a database of points. My interest is obviously related to how to produce a dilation structure from the knowledge one has about a metric space at different scales and some symmetries (here the euclidean group). That is why I was interested in euclideon from the first time, because they have found a way which is not based on octrees (relatd to bsp, a bit, maybe?), raytracing and alike. I shall eventually figure it out, because I am a stubborn mathematician, but it would be so nice to just share new (mathematical) ideas.
Rant. This is what I try to do on this blog, anyway: sharing my ideas with the hope to find alike minded humans which could contribute too, coming with their ideas and so on. There is the matter of who did it first, but these days the solution is, I think, just to be as open as possible. Google takes care of the rest. (That is along another set of ideas I try to push on this blog, on the green open access publication model. Any time when somebody borrowed one of my ideas and published it in old-school classic journals, without citing me, I sang Janice Joplin’s “Take it! Take another little piece of my heart…” because I have many more to spare. But anyway, sometimes it makes you feel nice when — rightfully — acknowledged, and this is something more likely to happen in a green open access model.)
Hi, chorasimila.
>Re: “all these points sorted and linked with each other … in special way”. That is what I want to understand, from pure mathematical reasons. Could you tell me this?
Now I worked and thought enough to reveal all the details, lol.
I may dissapoint you: there’s no much mathematics in what I did. JUST SOME VERY ROUGH BRUTE-FORCE TRICKS. In short: I render cubemaps but not of pixels – it is cubemaps of 3d points visible from some center. When camera is in that cubemap’s center – all points projected and no holes visible. When camera moves, the world realistically changes in perspective but holes count increases. I combine few snapshots at time to decrease holes count, I also use simple hole filling algorithm. My hole filling algorithm sometimes gives same artifacts as in non-cropped UD videos (bottom and right sides), this confirms that UD has holes too and his claim “exactly one point for each pixel” isn’t true.
I used words “special”, “way”, “algorithm” etc just to fog the truth a bit. And there is some problems (with disk space) which doesn’t really bother UD as I understand. So probably I my idea is very far from UD’s secret. Yes, it allows to render huge point clouds but it is stupid and I’m sure now it was done before. Maybe there is possibility to take some ideas from my engine and improve them, so here is the explanation (again sorry for my English):
Yes, I too started this project with this idea: “indexing is the key”. You say to the database: “camera position is XYZ, give me the points”. And there’s files in database with separated points, database just picks up few files and gives them to you. It just can’t be slow. It only may be very heavy-weight (impossible to store such many “panoramas”) . I found that instead of keeping _screen pixels_ (like for panoramas) for each millimeter of camera position it is possible to keep actual _point coordinates_ (like single laser scanner frame) and project them again and again while camera moves and fill holes with other points and camera step between those files may be far bigger than millimeters (like for stereo-pairs to see volumetric image you only need two distant “snapshots”).
By “points linked with each other” I meant bunch of points linked to the some central points. (by points I mean _visible_ points from central point). What is central point? Consider this as laser scanner frame. Scanner is static and catches points around itself. Point density near scanner is high and vice versa.
So again: my engine just switches gradually between virutal “scanner” snapshots of points relative to some center. During real-time presentation, each frame few snapshots projected, more points projected from the nearest, less from far snapshots. Total point count isn’t very big, so real-time isn’t impossible. Some holes appear, simple algorithm fills them using only color and z-buffer data.
I receive frames(or snapshots) by projecting all the points using perspective matrix, I use fov 90, 256×256 or 512×512 point buffer (like z-buffer but it stores relative (to the scanner) point position XYZ). I do this six times to receive cubemap. Maximum points in the frame is 512x512x6. I can easily do color interpolation for the overlapped points. I don’t pick color of the point from one place. This makes data interleaved and repeated.
Next functions allow me to compress point coordinates in snapshots to the 16bit values. Why it works – because we don’t need big precision for distant points, they often don’t change screen position while being moved by small steps.
int32_t expand(int16_t x, float y)
{
int8_t sign = 1;
if (x<0) { sign = -1; x = -x; }
return (x+x*(x*y))*sign;
}
int16_t shrink(int32_t z, float y)
{
int8_t sign = 1;
if (z<0) { sign = -1; z = -z; }
return ((sqrtf(4*y*z+1)-1)/(2*y))*sign;
}
I also compress colors to 16bit. I also compress normals to one 24bit value. I also add shader number (8bit) to the point.
So one point in snapshot consists of:
16bit*3 position + 24bit normal + 16bit color + 8bit shader
There must be some ways to compress it more (store colors in texture (lossy jpeg), make some points to share shader and normals).
Uncompressed snapshot full of points (this may be indoor snapshot) 512x512x6 = 18Mb
256x256x6 = 4,5Mb
Of course, after lzma compression (engine reads directly from ulzma output, which is fast) it can be up to 10 times smaller, but sometimes only 2-3 times.
AND THIS IS A PROBLEM. I'm afraid, UD has smarter way to index it's data.
For 320×240 screen resolution 512×512 is enough, 256×256 too, but there will be more holes and quality will suffer.
To summarize engine's workflow:
1) Snapshot building stage. Render all scene points (any speed-up may be used here: octrees or, what I currently use: dynamic point skipping according to last point distance to the camera) to snapshots and compress them. Step between snapshots increases data weight AND rendering time AND quality. There's no much sense to make step like 1 point. Or even 100 points. After this, scene is no longer needed or I should say scene won't be used for realtime rendering.
2) Rendering stage. Load nearest snapshots to the camera and project points from them (more points for closer snapshots, less for distant. 1 main snapshot + ~6-8 additional used at time. (I am still not sure about this scheme and changing it often). Backfa..point culling applied. Shaders applied. Fill holes. Constantly update snapshots array according to the camera position.
If I restrict camera positions, it is possible to "compress" huge point cloud level into relatively small database. But in other cases my database will be many times greater than original point cloud scene.
Next development steps may be: dynamic camera step during snapshot building (It may be better to do more steps when more points closer to camera (simple to count during projection) and less steps when camera in air above the island, for example), better snapshot compression (jpeg, maybe delta-coding for points), octree involvement during snapshot building. But as I realized disk memory problems, my interest is falling.
Any questions?
What happens if the camera snapshot point is really close or inside an object?
If the render camera is then outside the object in that particular cube then it won’t show anything.
As far as compression is concerned, he doesn’t used normals, everything is pre-lit, and it always has been, and there is no shader values. And the colour cube-map can be a single jpeg because it’s quality is not necessarily needed for position and with it’s a natural compression the eye doesn’t really see many artifacts.
A problem though. Here, go to 06:55 on this video:
You can see the horizontal stripes on the floor going from dark green to light green. These look like perspective LOD bands to me. Along with the mess on the right and bottom of the screen makes me still believe they’re using something like Donald Meagher’s octree then quadtree 2D splatting routines. Oh I don’t know, I guess I have to code something up when I have time and just try it. 🙂
Dave H.
I am wondering what those lines are. Could it be some interference between the pointcloid grid, and a raycast-like grid?
So, if a point wich can be seen from 100 panorama poins, does it mean that the data of that one point equals to data of 100points?
I don’t know, do you think at data as something which is an additive quantity? Is not.
Hi, Kais, is that you?
>As far as compression is concerned, he doesn’t used normals, everything is pre-lit, and it always has been
But look at 4:36 in your video, it doesn’t look pre-lit.
>What happens if the camera snapshot point is really close or inside an object?
>If the render camera is then outside the object in that particular cube then it won’t show anything.
Are you speaking about snapshot preparation process? Possible solution is to generate them with dynamic step – do more steps near the surfaces and inside objects if you wish.
Anyway I gave up on that thing (snapshots) (although it was most clear solution for me) and looking for new methods with more balance between preprocessed data and on-the-fly computing (less data, but managed to allow more effective computations).
>mess on the right and bottom of the screen
I’ve read some my old notes about the algorithm in my demo you probably saw (the one with gray rocks), don’t know if you noticed similar artifacts in it. And now I think that that “mess” may be result of some rough kind of viewport clipping speed-up.
Lately I said “this may be caused by hole-filling algorithm” – I was wrong (however my hole-filling algorithms may cause something like that too), it’s more likely just skipping of excessive data: I received that artifacts because I decided to skip few points when they start to project outside the viewport, this gave me speed up and also that aritfacts (can’t find the code to say more accurately).
>You can see the horizontal stripes on the floor going from dark green to light green. These look like perspective LOD bands to me.
Yes, he’s definitely using octree but I want to notice, that stripes has strange U-, sometimes V-like form, they do not surround viewer, but the point far forward. Usually LOD levels surround the camera due to formulas like: LOD = MaxDepth – Distance(Voxel, Camera)*someKoeff
and have arc shape (not U, but reversed U) so maybe it’s not LODs but another key to the secret.
“…so maybe it’s not LODs but another key to the secret.”
Yes, is Level Of Distance 😉 . From infinity.
>But look at 4:36 in your video, it doesn’t look pre-lit.
He can store anything in the data, and 4:36 shows an early sparse object demo. The later ones had a 1 bit shadow map, as he explains. I’m not sure why they needed a separate shadow map at all, as they could bake in the lighting. Strange.
The ‘landscape’ videos have no lights at all, well if they did, why didn’t they at least move the sun around a bit to show it off. And what would happen to his shadow map then, would it move correctly? It appears to flicker like crazy on some of videos.
IF they are storing cube-maps like you suggest, then their compression ratio gets better and better the higher the resolution of the original data becomes, because the data size is always relative to the size of the screen, not the underlying model.
Why are the errors always on the right and bottom, why not top and left?
Thinking about the green bands again. It looks like he’s displaying the number of steps taken to reach a point, like rendering distance fields. So edges with detail get homed in on but take longer to reach. His octree patent is a bit of a give away of course!!! So I guess they’re not using your snapshot idea in their renderer after all.
As a side note to the discussion in this video if you pause it somewhere at 02:47 (it’s quite difficult to catch it perfectly).
At 2:47 you will see a closeup of one of those water plants as it flashes past from left to right. You can see the ‘atoms’ as camera facing squares. Quite bizarrely, in that close up there’s a mixture of low and high resolution edges to the leaves. An effect generated by the compression perhaps?
It’s nice to have a discussion about it anyhow, although anything is better than the old “Minecraft’s Notch said it’s fake, he’s a genius so he must be right” – kind of arguments I get on YouTube!! 🙂
This post is seen a lot lately, even if old (many old posts from this blog are still having hits). I wonder why do you look at it, if there’s no action associated, AFAIK? If there is one, please leave a note.
Its has been a long time. Symbolic Volumetric Language (SymVOL) development moves forward. It now has fields of influence to control volumetric material distribution and any other variables desired. This new addition is again is only limited by the mathematical resources. In the middle of 2016 SymVOL was tested with a volumetric model of complex cellular and vascular structures printed with 8 different materials at one micron level of precision. A slice / CNC path for a large industrial 3D printer about to be made public was processed within seconds. A print spool of 20mb was all that was needed. Some technical problems with the hardware has delayed its release.